搭建流程概览
欢迎加群沟通交流:955097147;
有点糊,凑合看;

前期工作
基础操作系统
本流程全部基于ubuntu-22.04.2-live-server-amd64这个镜像安装的基本系统(可以是虚拟机,也建议部署虚拟机),当然选择macOS、unraid、群晖甚至是windows都可以,只要你能够完全理解docker并解决兼容性问题即可;
如果担心解决不了兼容性问题,那就完全按照我的流程来,99%的问题都可以避免;
魔法环境
因为一些众所周知的原因,国内IP无法访问docker了,所以想要pull docker镜像,就得用点小手段,具体的操作B站上有很多,自行搜索解决。
飞书文档账号
飞书和抖音一家的,有抖音号就能用手机号登录飞书;
飞书开放平台:https://open.feishu.cn/app?lang=zh-CN
从以上地址申请一个应用,然后开通API,备用。
硅基流动账号
访问地址:https://cloud.siliconflow.cn/
直接手机号登录,直接赠送14元2000W的token额度,可以白嫖用很久;
https://cloud.siliconflow.cn/i/uTfmHCxU(这是我的邀请码,用不用都会赠送14元,不过用了我也会拿到14元~)
 (不过看图片里的活动说明,好像要受邀才赠送。。。我也记不清我当初有没有用邀请码了)
(不过看图片里的活动说明,好像要受邀才赠送。。。我也记不清我当初有没有用邀请码了)
本地有显卡的,可以不用这个,部署ollama,直接用qwen2.5:7b,效果也很好;
部署ubuntu虚拟机
安装Virtual Box
安装程序的下载地址:https://www.virtualbox.org/,直接Download最新版本即可
根据你的平台下载即可(下载速度贼慢的,可以从我文章末尾提供的阿里云盘链接下载);
搭建Dify平台
前提条件:已经安装完成Ubuntu,如果你安装了windows docker或者使用其他平台的docker,直接跳转到:可选:安装portainer ce
安装docker
确保已经安装了Docker。如果没有安装,可以使用以下命令安装Docker:
sudo apt update
sudo apt install docker.io验证是否安装成功
docker --version成功则显示
llm@llm:~$ docker --version
Docker version 26.1.3, build 26.1.3-0ubuntu1~22.04.1
安装Docker Compose
下载Docker Compose二进制文件。您可以访问 Docker Compose官方GitHub发布页面 来找到最新版本的下载链接。以下是安装Docker Compose的命令:
sudo apt install curl
sudo curl -L "https://github.com/docker/compose/releases/download/v2.5.0/docker-compose-$(uname -s)-$(uname -m)" -o /usr/local/bin/docker-compose修改二进制文件的执行权限:
sudo chmod +x /usr/local/bin/docker-compose验证安装是否成功:
docker-compose --version能正常输出docker-compose的版本就算安装成功了。
如果下载失败,提示 Could not resolve host: github.com
解决办法为更换dns,
sudo nano /etc/resolv.conf
将dns更换为8.8.8.8
如果还是下载不了,要科学上网~
可选:安装portainer ce
这玩意可算,管理docker比较方便,已经汉化,方便使用:
sudo docker pull 6053537/portainer-ce
sudo docker volume create portainer_data
sudo docker run -d --name portainer -p 9000:9000 --restart=always -v /var/run/docker.sock:/var/run/docker.sock -v portainer_data:/data 6053537/portainer-ce可选:安装Ollama(本地没有显卡不要装)
本地没有显卡的就别装了, 直接用在线大模型;
6G以上显存的可以来一波:
docker run -d -v ollama:/root/.ollama -p 11434:11434 --name ollama ollama/ollama安装Dify
cd ~
git clone https://github.com/langgenius/dify.git
cd dify/docker
cp .env.example .env
sudo docker compose up -d 全部启用完成后,从浏览器访问:http://ubuntu的ip地址;即可访问到dify
安装Dify完成后,我们先放到一边,进行其他的准备工作;
配置大模型服务
获取供应商API
浏览器访问:https://cloud.siliconflow.cn/i/uTfmHCxU(介意者去掉我的邀请码,一样可以注册);
可以使用手机号注册或者使用Google、Github账号直接登录:
注册完成后要实名认证,然后点击右侧API选项卡:
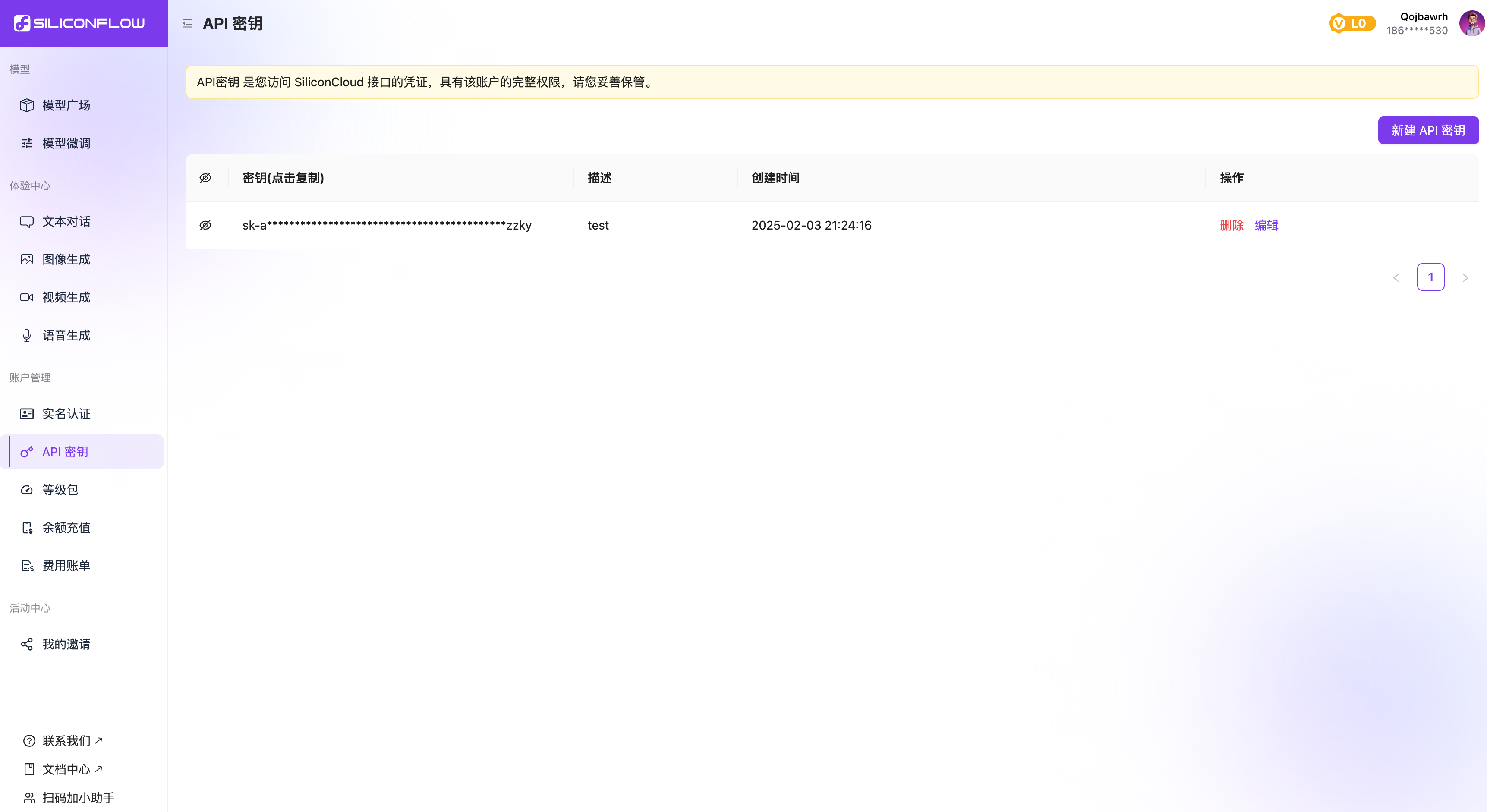
点击新建API秘钥,随便写个描述,然后复制得到的密钥:
获取硅基流动的对话、嵌入模型、重排序模型
打开硅基流动的模型广场,可以看到有六类模型:
对话(就是我们常用的LLM模型,本教程必选项)
生图(文生图用的)
嵌入(知识库量化时使用的,本文必选项)
重排序(提升知识库的匹配率,本文可选项)
语音(文转语音以及反向)
视频(没研究过。。。不不确定是不是文生视频,也可能是多模态)
我们要使用的就是对话、嵌入、重排序模型;
关于对话模型:虽然硅基流动提供了所谓满血Deepseek,但是基本上无法响应,可用的满血模型是Pro/deepseek-ai/DeepSeek-R1和Pro/deepseek-ai/DeepSeek-V3这俩,但是赠送余额不能用,充值才可以(我反正不用);
本文所使用的智能AI客服,我实测了只要7B的模型就能整儿八经的跑起来,所以这里面的模型大家闭着眼选一个32B及以上的参数量,妥妥的是没问题的,我个人建议使用Qwen系列;
建议使用的对话模型:Qwen/Qwen2.5-7B-Instruct(目前免费随便用)、Qwen/Qwen2.5-14B-Instruct(意图识别方面理论上效果更好一些);
建议的嵌入模型、重排序模型名称(直接复制):
嵌入模型:netease-youdao/bce-embedding-base_v1
重排序模型:netease-youdao/bce-reranker-base_v1
模型已经都有了,大家直接复制名字,接下来配置到dify中;
模型有了,客服流程的最后一步就是飞书云文档的API了;
配置飞书云文档
飞书的API概念
今天更新文档之前有小伙伴告诉我被这部分给搞晕了, 其实我在不部署的时候疯狂吐槽字节的API设计,为了安全搞得确实麻烦的要命;
今天在开始配置之前,我认为有必要先让大家搞清楚飞书的各种Token和key到底是干嘛的?从哪里获取?
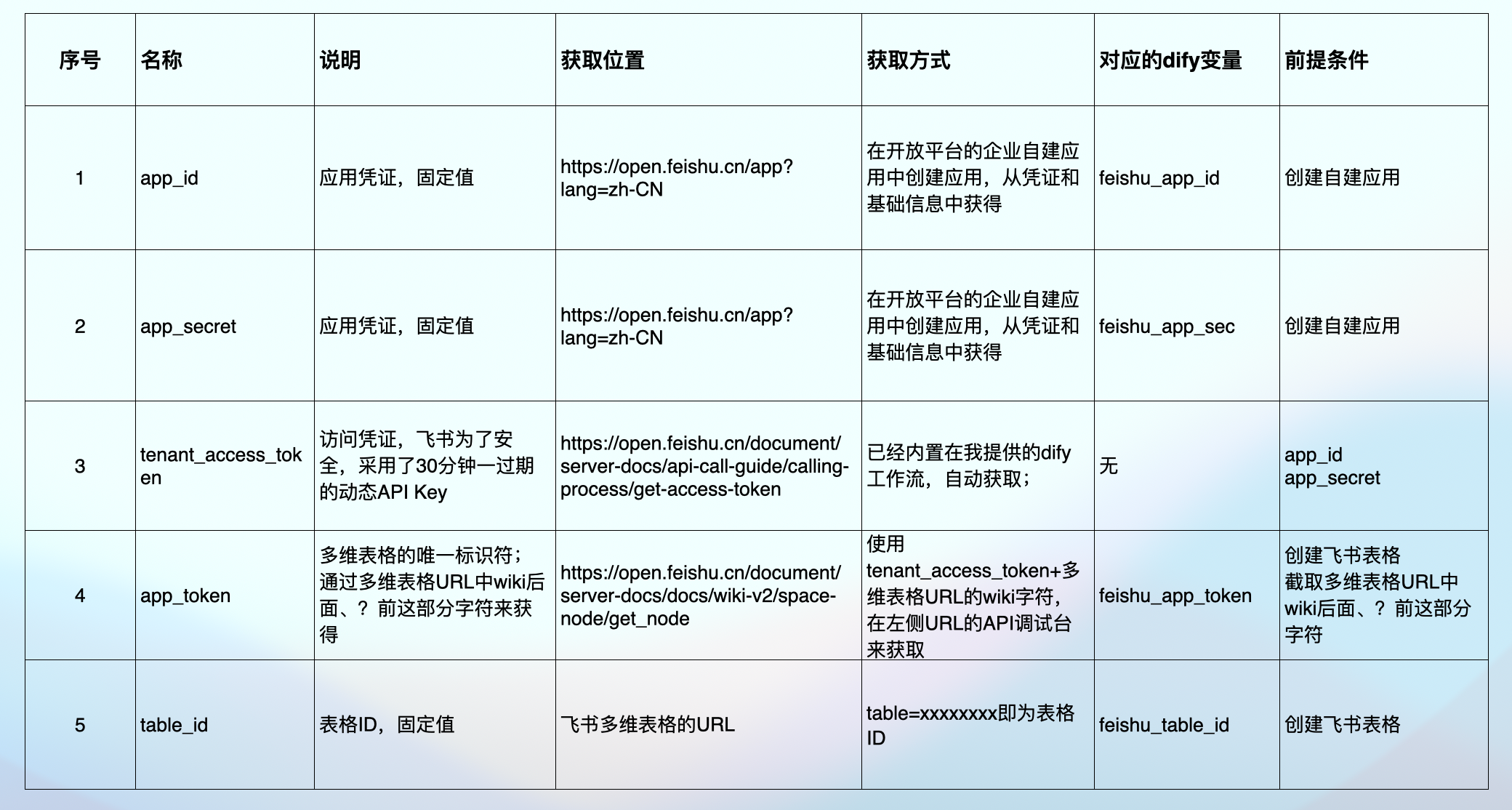
名称及获取位置:
app_id : https://open.feishu.cn/app?lang=zh-CN
app_secret: https://open.feishu.cn/app?lang=zh-CN
tenant_access_token:https://open.feishu.cn/document/server-docs/api-call-guide/calling-process/get-access-token
app_token :https://open.feishu.cn/document/server-docs/docs/wiki-v2/space-node/get_node?appId=cli_a7c79cc71c24900e
table_id :飞书多维表格的URL
创建多维表格
访问:https://feishu.cn/drive/home ,即可打开飞书云文档的首页;
直接点击新建多维表格
或者直接复制我分享的表格,相关的智能字段都已经创建完成:
https://ocnjcezdgcjy.feishu.cn/base/TD48bpTIUa8cFGszunqcZu2enHd?from=from_copylink
复制完成后,其中带”AI”标识的智能字段的总结内容需要根据你自己的实际业务情况来修改
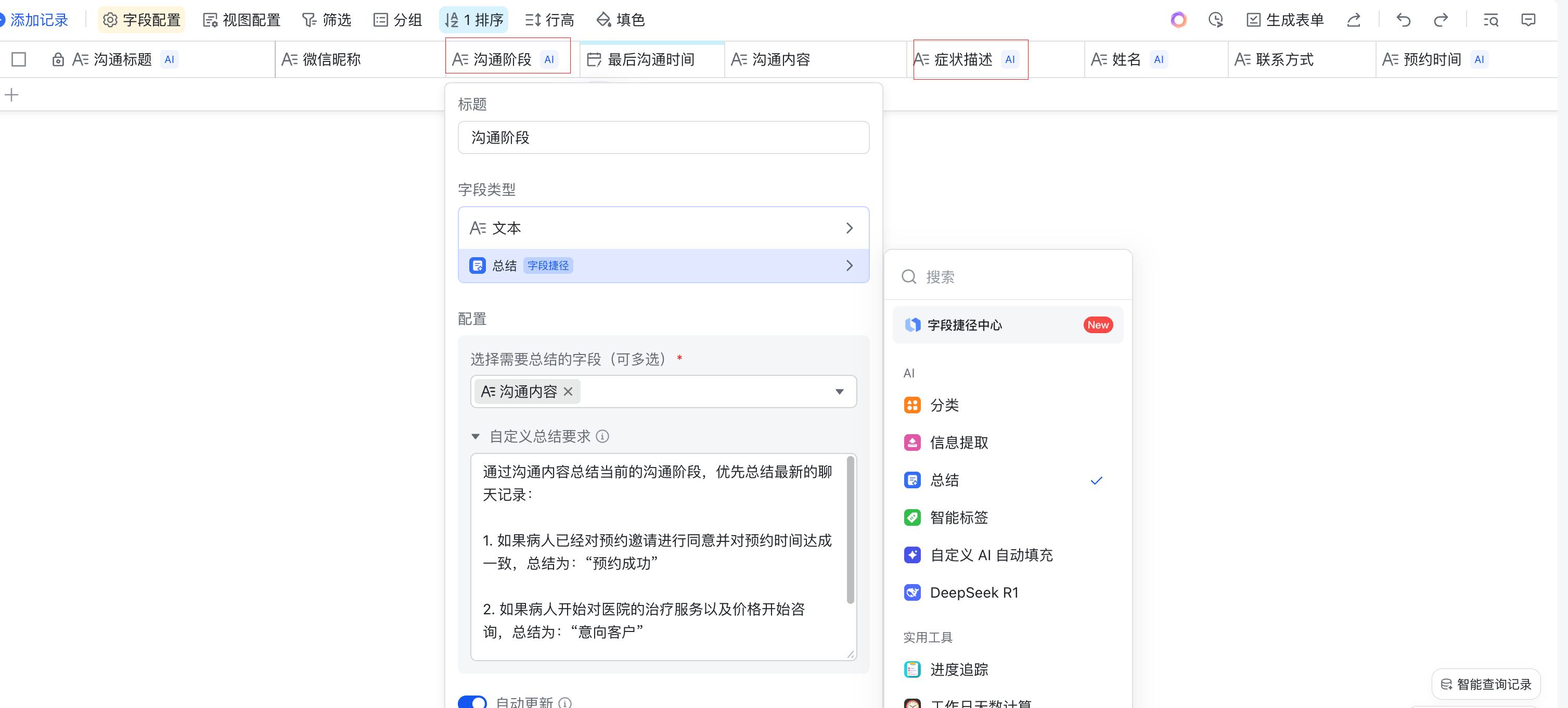
获取对应的飞书表格ID、Token
参考这个表格进行获取,然后填入到dify工作流中
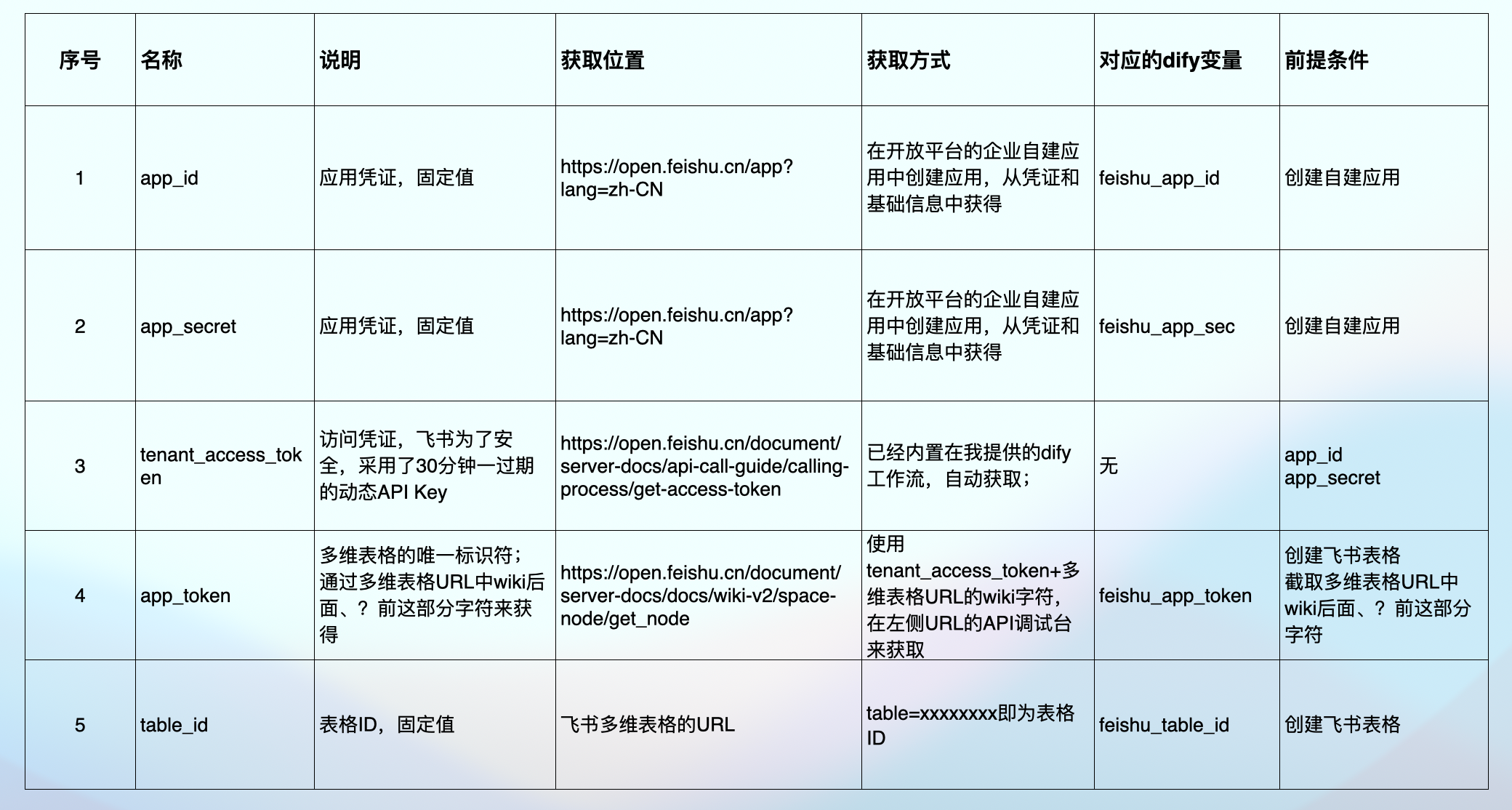
名称及获取位置:
app_id : https://open.feishu.cn/app?lang=zh-CN
app_secret: https://open.feishu.cn/app?lang=zh-CN
tenant_access_token:https://open.feishu.cn/document/server-docs/api-call-guide/calling-process/get-access-token
app_token :https://open.feishu.cn/document/server-docs/docs/wiki-v2/space-node/get_node
table_id :飞书多维表格的URL
配置Dify工作流
配置流程概览
Dify安装完成以后,需要做三部分操作才能正常使用我制作的智能客服流程:
配置模型提供商(下一章节中介绍如何配置硅基流动LLM模型);
配置知识库;
导入工作流文件;
填写飞书中获取Key
配置模型供应商
登录到Dify界面,点击右上角的头像,选择设置
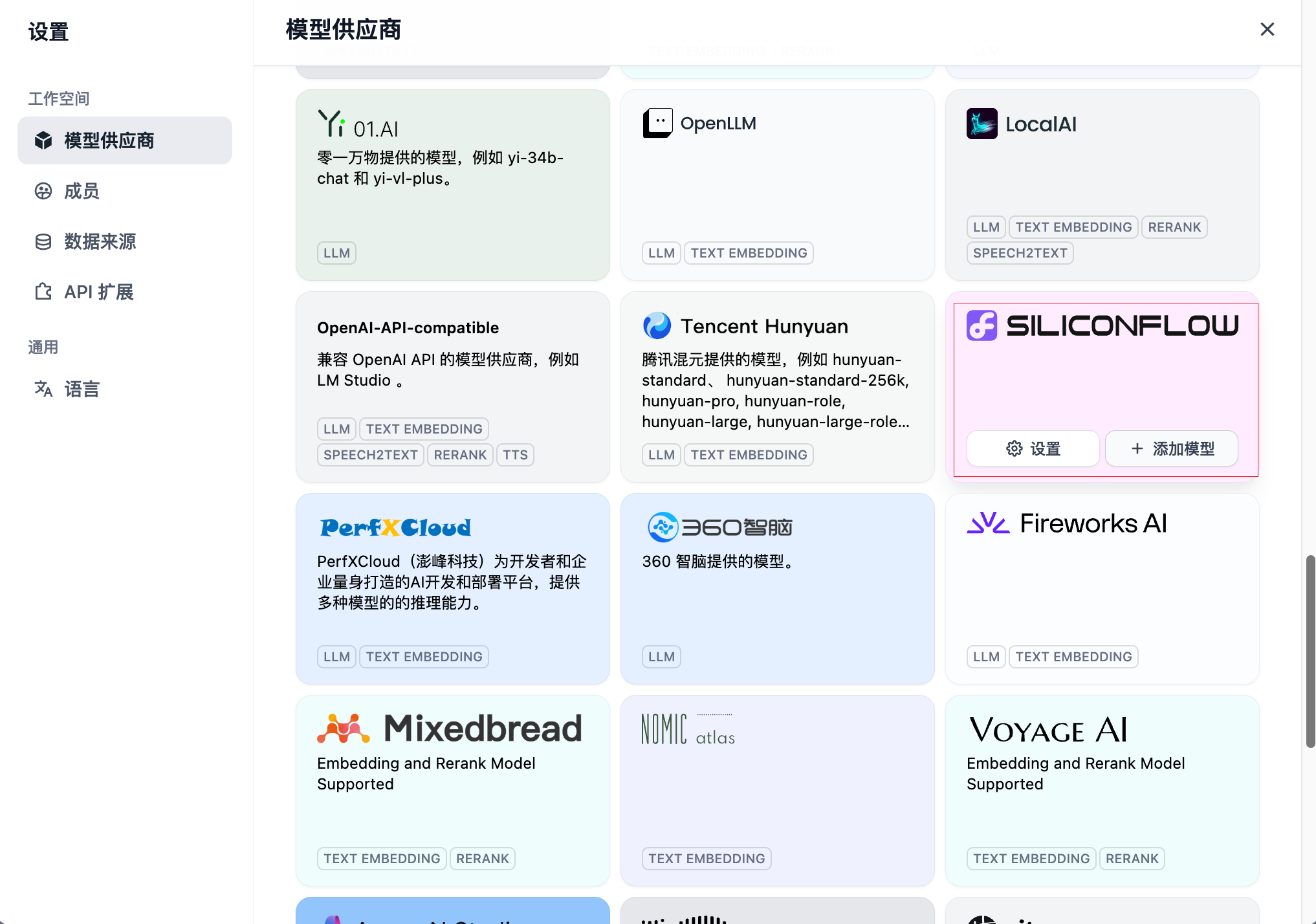
点击模型供应商选项卡,往下拉找到硅基流动的供应商位置(siliconflow),点击设置
输入之前复制的API Key,点击保存

可以看到一大堆模型已经添加好了?!
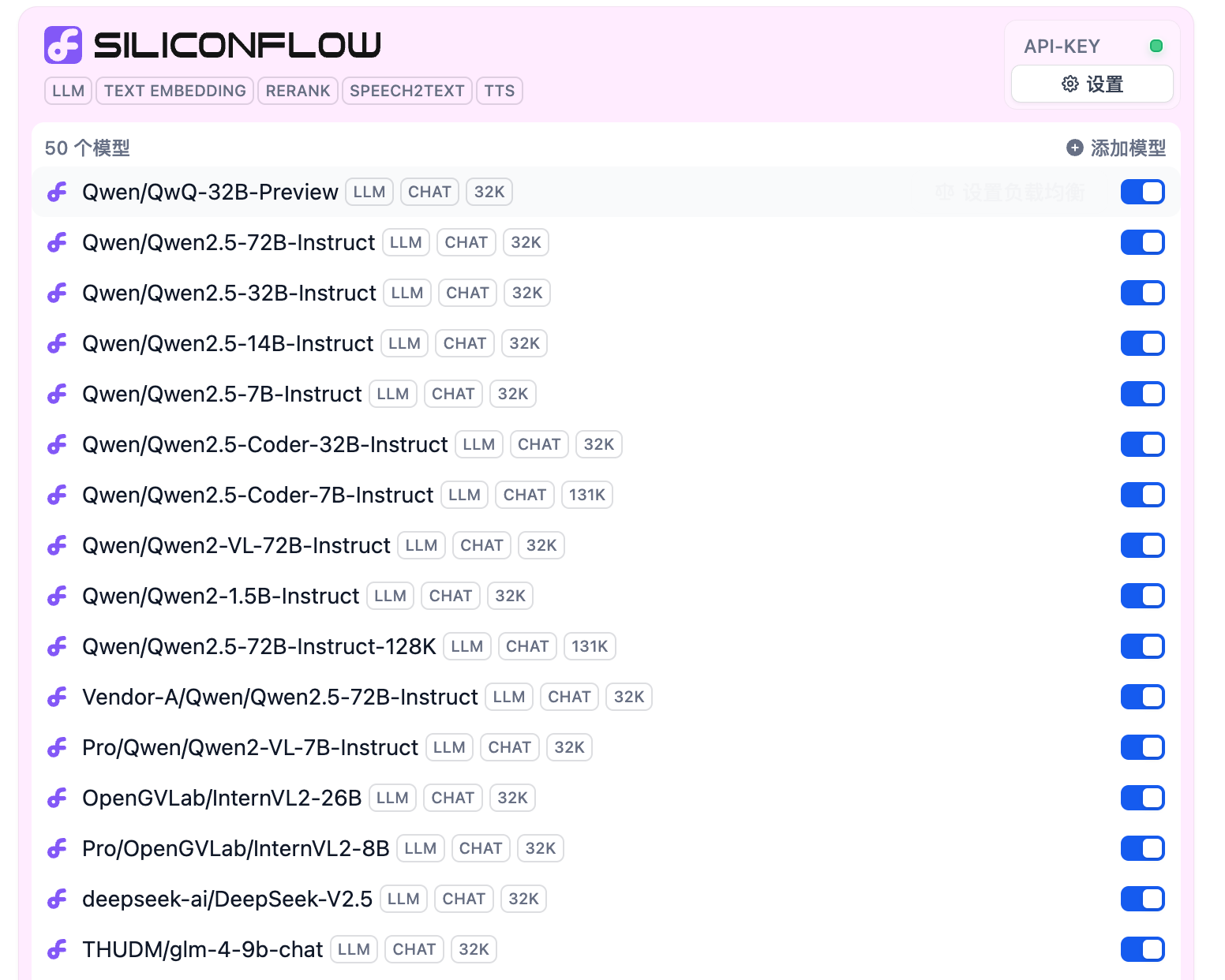
到这,模型就准备完成了(Dify对硅基流动的优化真不错,省事);
配置知识库
出于学习目的,可以先试用我提供的牙科客服的知识库示例文件:
牙痛咨询示例.txt
牙科问题交流.txt
点击即可下载。
新建知识库之前,需要配置向量模型以及重排序模型(硅基流动提供在线的模型,如果按照我上的步骤,那已经配置好了);
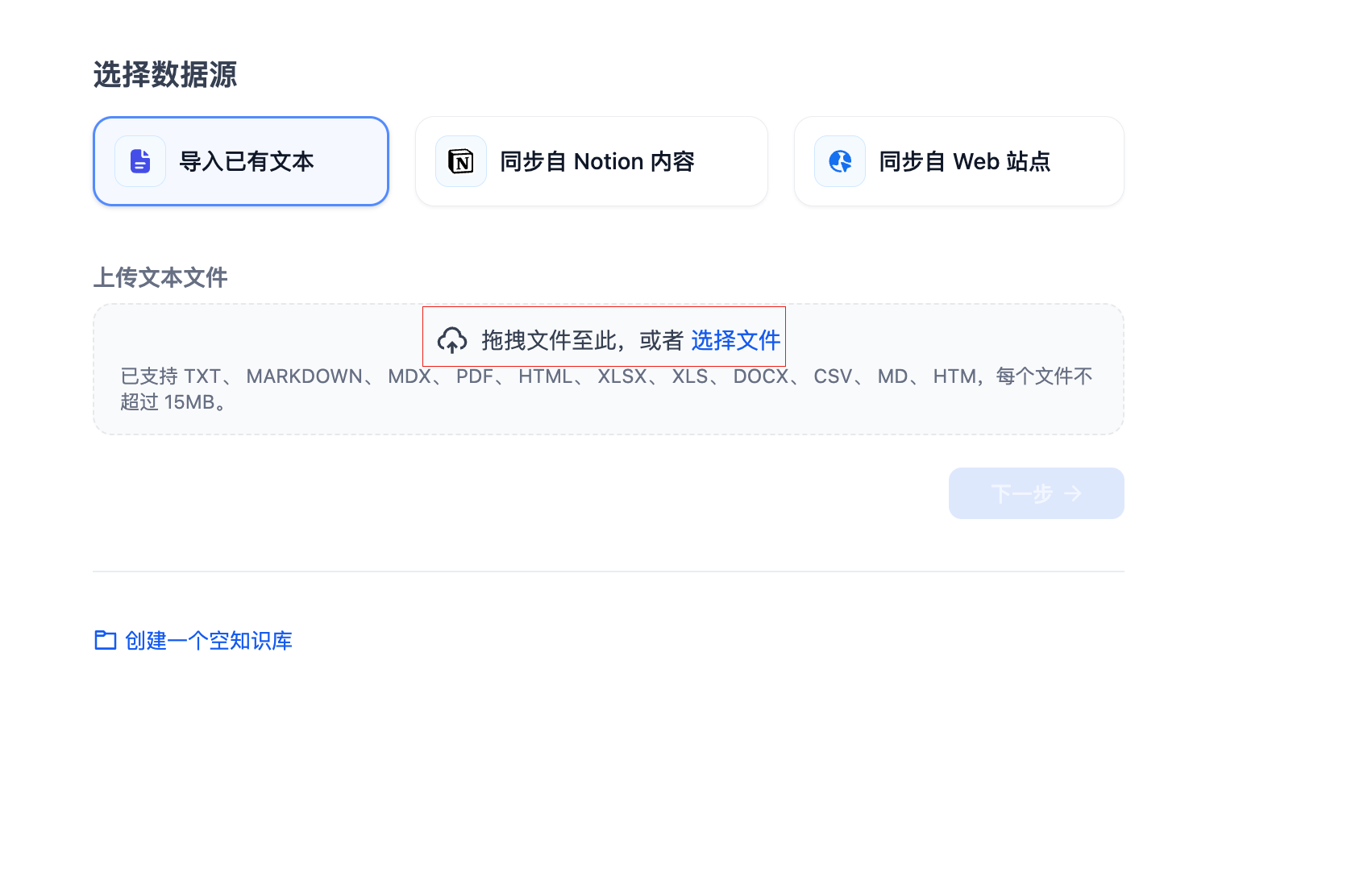
选择下载的知识库示例文件并上传,点击下一步
选择好对应的embedding模型和rerank模型,检索设置选择混合检索;分段设置根据需要选择通用还是父子分段;
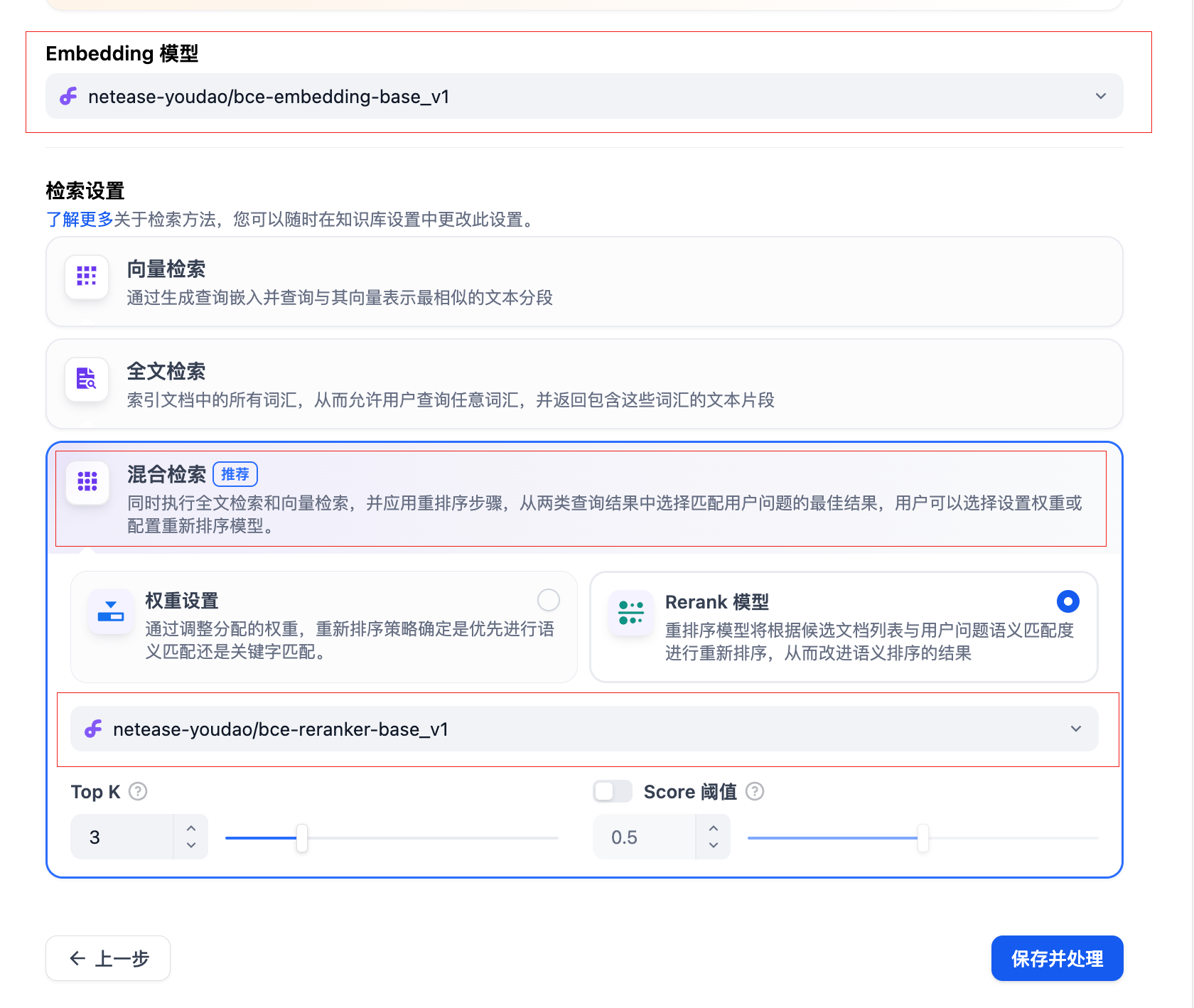
点击保存并处理,知识库就创建完成了。
导入工作流文件
B站视频中的dify工作流文件:
选择导入DSL文件,上传上面下载的工作流模板.yml文件,导入完成。
修改模型以及填写环境变量
修改工作流中所有黄色叹号的节点,这说明没有选择有效的模型,直接编辑节点,选择硅基流动的LLM模型即可
填写会话变量,图中这四个必填;
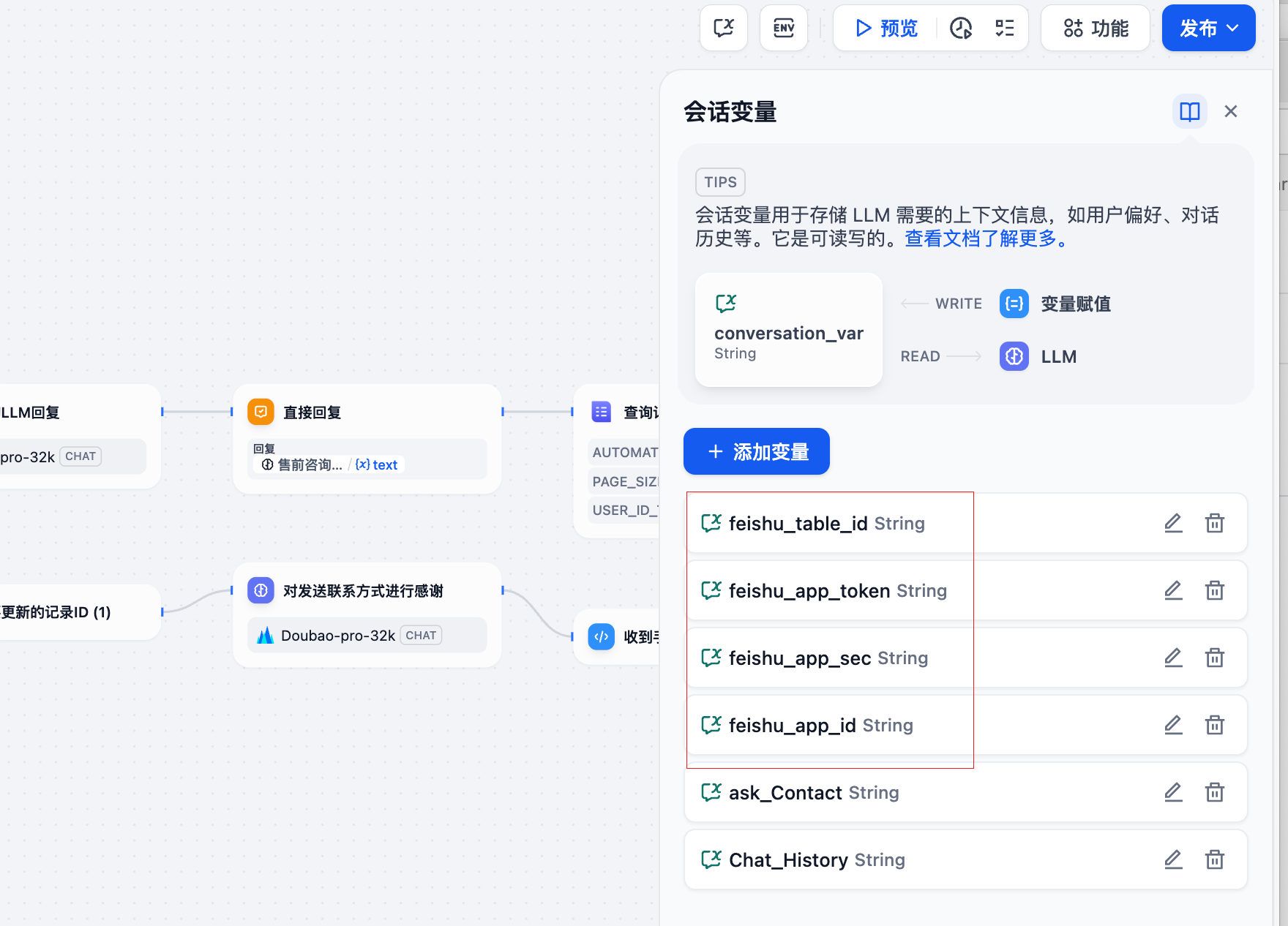
方便你们查看,这里再贴一次图
至此,该工作流已经可以正常运行了,点击发布即可API调用或者使用内置的页面进行访问:
对接微信
这方面我最近了解到了langbot,这玩意似乎比dify on wechat还要好用,我先研究一下,晚点补文档和视频。